MatToolBench
A real-environment benchmark for multimodal agents working with professional materials science software, covering GUI operation, code execution, and cross-tool workflows.
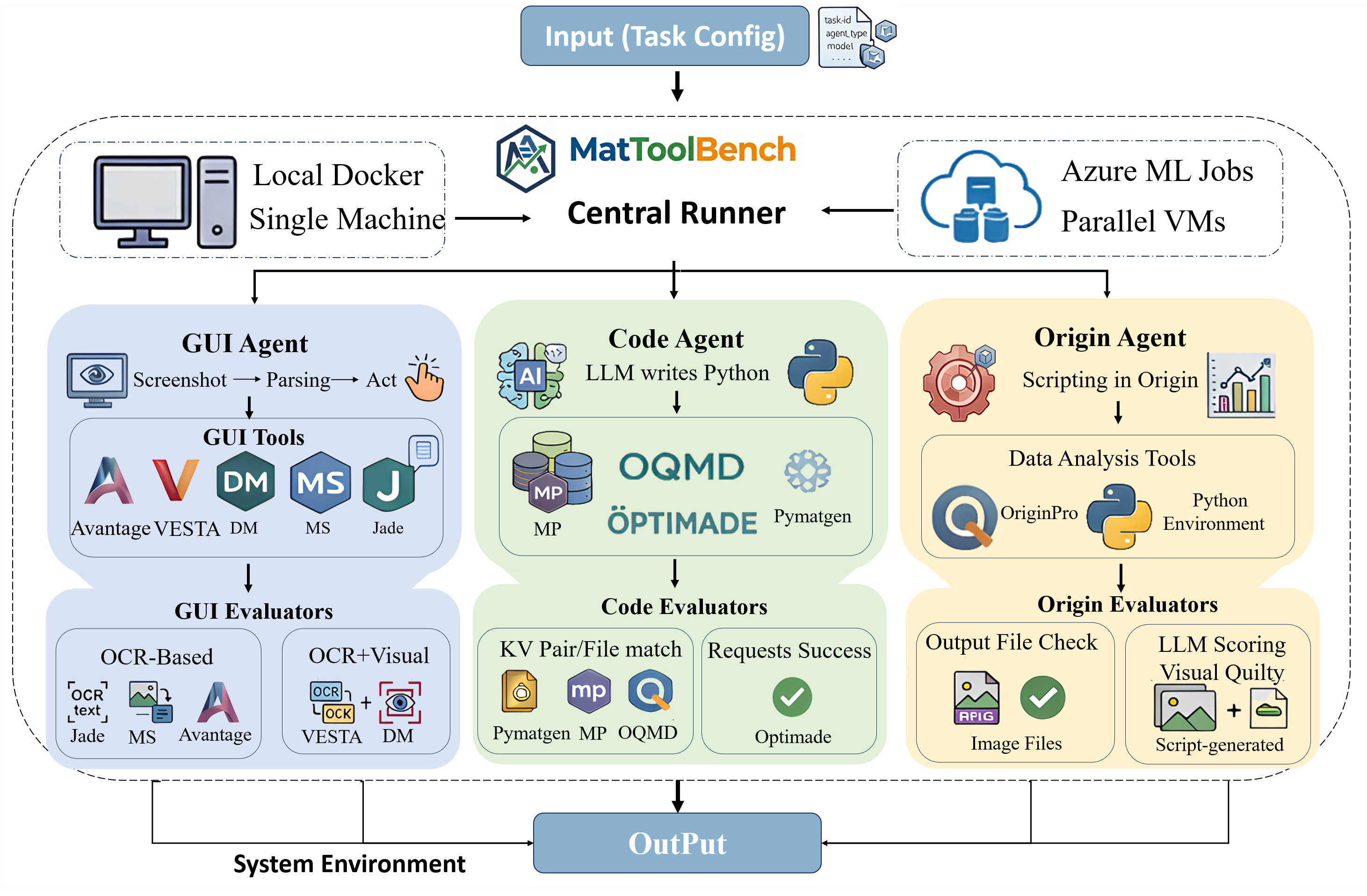
Problem
Multimodal agents are usually measured on general-purpose software, leaving a major gap in our understanding of how they perform in scientific tools and professional workflows.
Key Contributions
- Led the design of a benchmark spanning multiple materials science tools and task modalities.
- Built isolated Windows-based execution environments with standardized reset and evaluation hooks.
- Helped define layered evaluation methods suited to outputs ranging from GUI states to scripts and result files.
Results
- Exposed a large performance gap between general benchmarks and professional software tasks.
- Created infrastructure suitable for reproducible large-scale evaluation.
- Made cross-tool agent workflows measurable rather than anecdotal.
Benchmark scope
MatToolBench covers a mix of GUI-heavy tools, code-oriented tools, and workflows that require moving across both. That mix matters because professional research software rarely fits into a single interaction pattern.
Systems contribution
The benchmark is not only a task list. It also depends on a stable runner, environment reset logic, and evaluation interfaces that match the outputs of different software systems. I spent much of my effort on that systems layer so the benchmark could scale beyond manually curated demos.
Research value
The result is a clearer picture of where general multimodal agents break down in specialized domains and what kinds of capabilities future systems need in order to become genuinely useful scientific assistants.